
We recently explored how we can take multiple seen image-to-image translators and reuse them to infer other unseen translations, in an approach we call mix and match networks, presented at CVPR 2018 (also IJCV 2020). The key is enforcing alignment between unseen encoder-decoder pairs.
In this post I will assume that you are familiar with generative adversarial networks (GANs) and image-to-image translation (e.g. pix2pix, CycleGAN). In a previous post I wrote about those topics.
Seen and unseen multi-domain image-to-image translations
Let us go step by step explaining this title, starting with image-to-image translation part. We first consider two image domains \mathcal{X} and \mathcal{Y} (or modalities, I will only mention domains for the moment for simplicity). Then we can define an image-to-image translation as the following mapping y=T_\mathcal{XY}\left(x\right) between an input image x\in \mathcal{X} and output image y\in \mathcal{Y} (some examples here). In general, this translation is implemented as an encoder-decoder pair, i.e. T_\mathcal{XY}\left(x\right)=g_\mathcal{Y}\left(z\right)=g_\mathcal{Y}\left(f_\mathcal{X}\left(x\right)\right), where f_\mathcal{X} is a domain-specific encoder (for domain \mathcal{X}), g_\mathcal{Y} is a domain-specific decoder (for domain \mathcal{X}), and z is a latent representation.
Now we move to the multi-domain part. Most image-to-image translation papers consider translations between two domains (i.e. input and output). Here we consider multiple domains and all the possible translations, as shown in the following figure.
A colored circle represents a domain \mathcal{X}^{(i)}, and an arrow (each direction) represents a specific encoder-decoder pair \left(f_i,g_j\right) implementing an image-to-image translation x^{(j)}=g_j\left(f_i\left(x^{(i)}\right)\right) from domain \mathcal{X}^{(i)} to domain \mathcal{X}^{(j)}. In this case all the possible pairwise combinations are trained explicitly (i.e. they are seen during training).
However, we can also consider the case in which only a few pairwise translations are trained (perhaps we do not have explicit data to train more, or it is too expensive to train all combinations). We refer to them as seen translations, and to the remaining as unseen translations. Our objective is to infer unseen translations from seen translations (i.e. train on seen and evaluate on unseen). For example, in the previous example with five domains:

If we can effectively infer these unseen translations, this can benefit other problems. For example:
- Scalability in multi-domain translations (e.g. recoloring, style transfer).
- Zero-pair cross-modal translation.
We will describe these two scenarios later, but first we introduce the mix and match networks approach.
Mix and match networks
A first way to solve an unseen translation is to find a path through seen translations from the input domain to the output domain, and cascade all the seen translators. For example, the translation from green to orange (\mathcal{X^{(5)}} to \mathcal{X^{(4)}}) in the previous example can be inferred indirectly as
using the blue domain (\mathcal{X^{(1)}}) as intermediate anchor domain. In this case the image is fully decoded to the intermediate domain and then encoded again.
Instead of relying on one or multiple intermediate domains, we propose to directly mix and match the encoder and decoder networks of the input and output domains, respectively. The translator is obtained by simply concatenating them. The unseen translation in the previous example is implemented with mix and match networks as
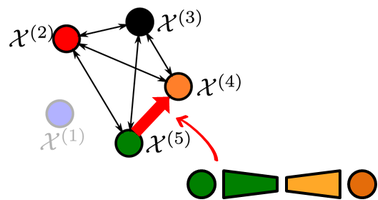
Note that in this case the green encoder and the orange decoder have not “seen nor talked” to each other directly during training, so somehow we need to ensure that they are able to communicate. This is achieved by forcing the encoder and decoders to be aligned, even in unseen cases. The latent representation in the bottleneck should be as domain-independent as possible.
Scalable multi-domain image-to-image translation
Now let us consider the previous example with five domains and train all the possible pairwise translators. Since every pair encoder-decoder is specific for a particular transformation, we have to train a total of 20 encoders and 20 decoders. In general, the number of encoders is N\left(N-1\right) (same for decoders).
Using mix and match networks with the blue domain as anchor, we can learn ten seen translations (i.e. five pairs of domains in both directions). In order to be able to infer the unseen translations we use two modifications:
- Shared encoders and shared decoders (i.e. one encoder and one encoder per domain).
- Autoencoders.
These two modifications encourage encoder-decoder alignment and a more domain-independent representation. In this case we only need five encoders and five decoders, and in general we only need N encoders and N decoders, which is much more scalable.
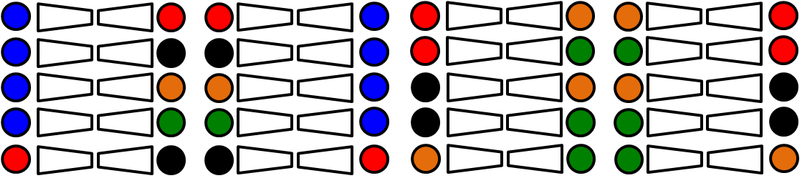
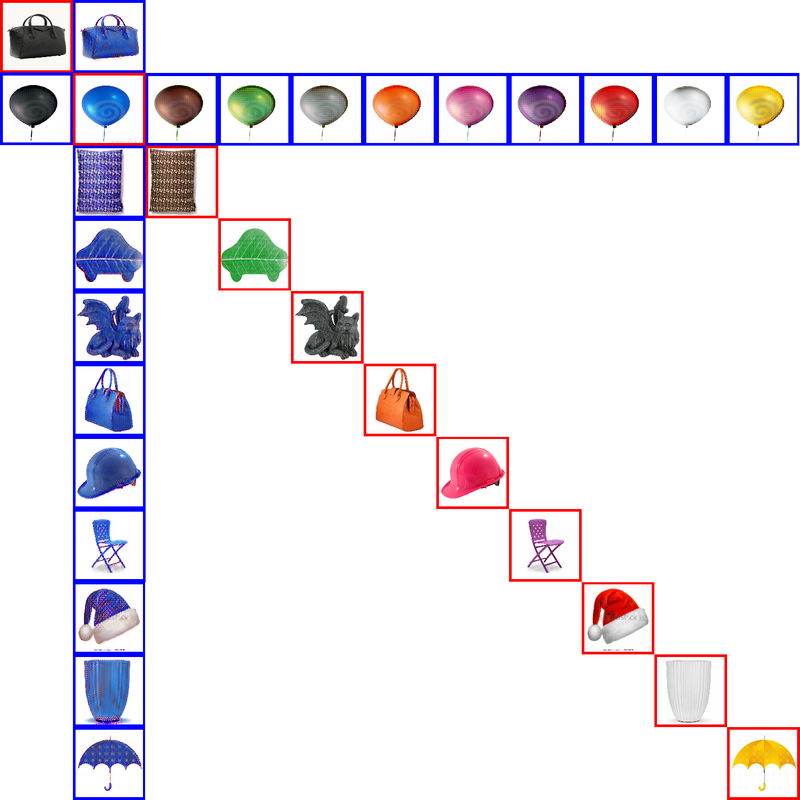
Color recoloring is a convenient problem to illustrate mix and match networks at work. Here we take eleven colors as the different domains and use the data from the colored object dataset. As in the previous example, we train mix and match networks (in this case we use CycleGANs, since the data is unpaired), using blue as anchor domain. In this case we obtain 11 encoders and 11 decoders (instead of the 55 encoders and 55 decoders of the full pairwise case). The following figure shows elevent test images, one from each domain.

Using the seen translators we obtain the following recolored objects (from blue to the other ten colors and from the other ten colors to blue)
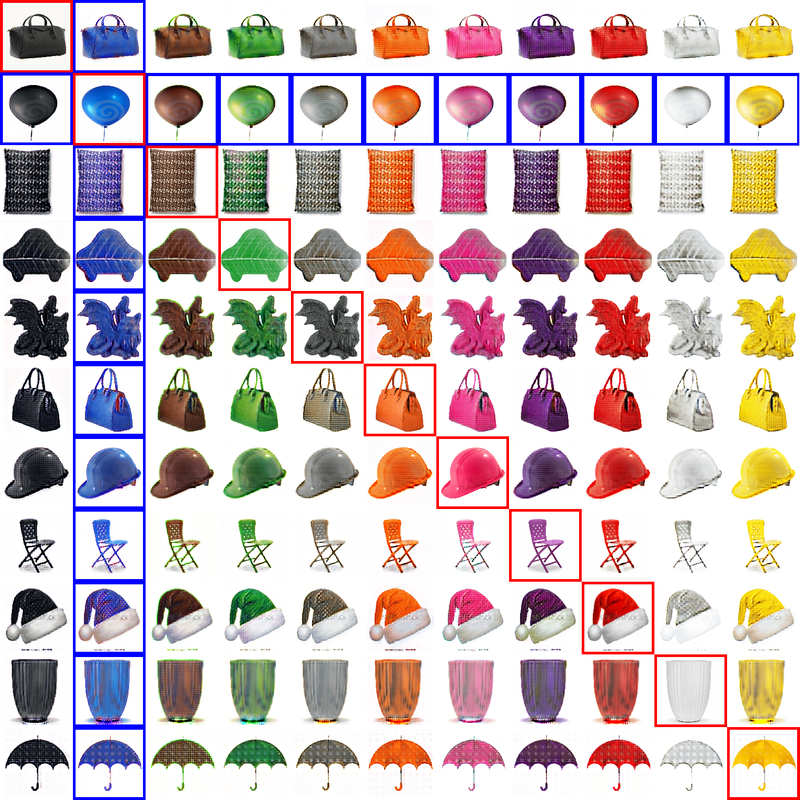
The remaining unseen translations between the other ten colors can be inferred, as shown in the following figure
Zero-pair cross-modal translation
Here we describe a more challenging and interesting scenario involving cross-modal translations and paired datasets. Imagine you have three modalities: RGB, segmentation and depth (yes, we keep using color coding). Our objective is going to be to learn cross-modal translations between depth and segmentation (in both directions). However we don’t have explicit (depth, segmentation) pairs for training, so those translations are unseen.
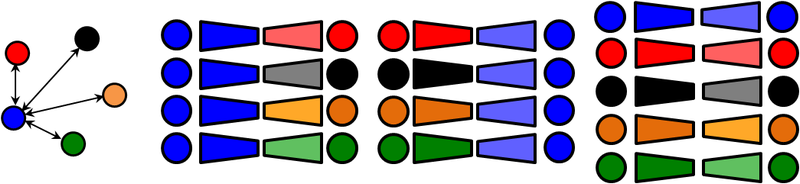
Paired, unpaired and zero-pair translation
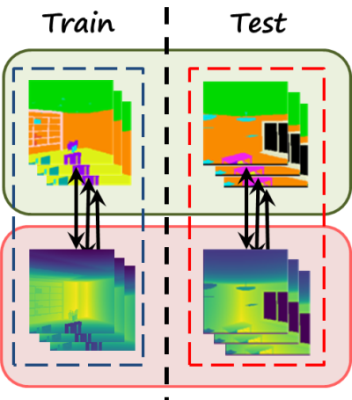
In general, we could learn to transform a depth image to segmentation (i.e. semantic segmentation from depth), or viceversa using a encoder-decoder framework and learn from paired images (following figure, left). We could also use a generic paired image-to-image translation method such as pix2pix. However, we can’t do that for unseen translations since we don’t have explicit pairs. In this case we still have a set of depth images and a set of segmentation maps, so we can consider unpair image-to-image translation (following figure, right), such as CycleGAN.
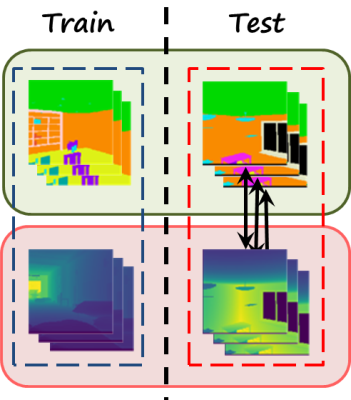
We consider a slightly different problem in which we have a third modality, and we have pairs between RGB and segmentation \left(x^{(R)},x^{(S)}\right)\in \mathcal{D}^{(1)} and pairs between RGB and depth \left(x^{(R)},x^{(D)}\right)\in \mathcal{D}^{(2)} . However, those sets are disjoint (i.e. from different scenes), so we still don’t have (depth, segmentation) pairs for the target translations, hence the name zero-pair.
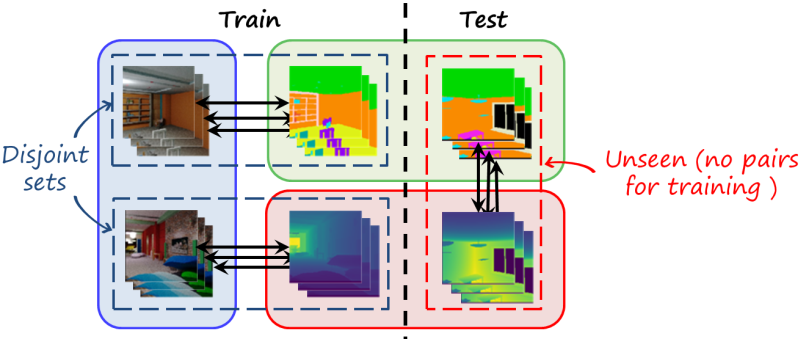
Baselines: cascaded translators and unpaired translation
As we did before, we can still find a path from the input domain to the output domain and concatenate seen translations via the RGB modality. Note that in this case each modality has its own reconstruction loss: L2 and GAN loss for RGB, cross-entropy for segmentation and Berhu loss for depth.
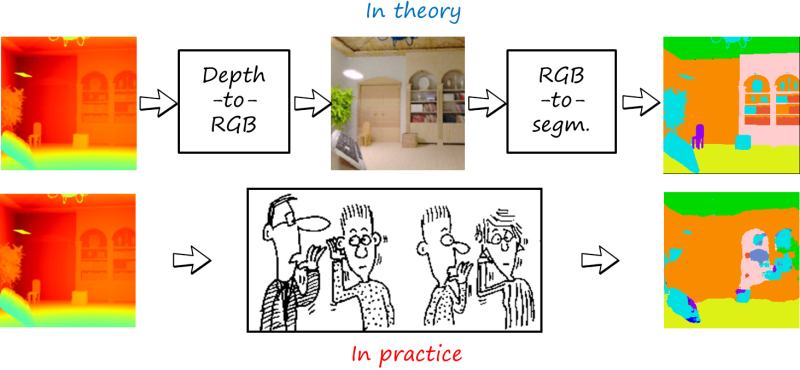
However this is not optimal, since requires fully decoding and encoding RGB images, and errors in each of the translations are accumulated. As in the Chinese whispers game, when the encoders and decoders are not good enough, part of the message is lost in communication path. In this case we see that the global layout of the scene is recovered, but it fails to reconstruct finer details such as small objects.
As we discussed before, we have pairs at the modality level so we can still formulate the problem as unpaired image-to-image translation. The following figure shows the result using CycleGAN.
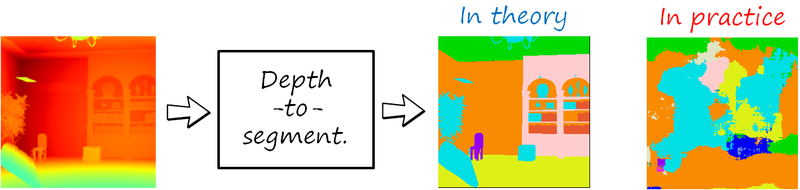
Note that the result is very disappointing, and not even a coarse layout is recovered. Unpaired image-to-image translation works well in cross-domain translation yet in the same modality (typically RGB) were the objective is basically to perform some changes in the certain local attributes, texture or colors (e.g. colorization, style transfer, change face attributes and expressions). However, this cross-modal problem is much more challenging since it requires deeper understanding of the semantics of the scene and change. This seems very difficult to address without the explicit guidance that the pixelwise correspondence in paired data provides .
Using mix and match networks
An alternative solution is aligning encoders and decoders so they can infer unseen translations, using the idea of mix and match networks. The following figure shows the framework which consists of two branches that implement the seen cross-modal translations and three modality-specific autoencoders. In addition to the encoders and decoders, there is also a discriminator, required to implement the GAN loss for the RGB modality.
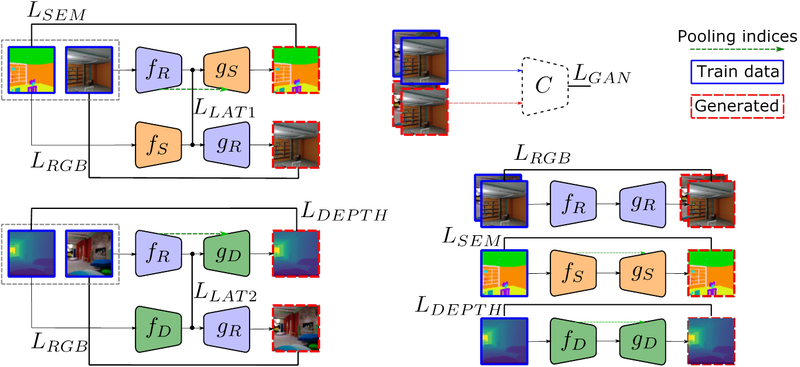
In addition to sharing modality-specific encoders and decoders, and modality-specific autoencoders, in this case we use two additional tricks to further facilitate a more effective communication between unseen encoders and decoders:
- Latent consistency losses. Our objective is to obtain latent representations where a scene is represented in the same way regardless of the particular input modality or the output modality. Since in this case we have input pairs that represent the same scene in two modalities, we can force the corresponding latent representations (after each modality-specific encoder) to be identical, by penalizing their difference. We use latency consistency losses on both (RGB, segmentation) pairs and (RGB, depth) pairs on the respective datasets \mathcal{D^{(1)}} and \mathcal{D^{(2)}} implemented as
L_{LAT} = \mathbb{E}_{\mathcal{D}^{(1)}}\left[ \left\| f_R\left(x^{(R)}\right) - f_S\left(x^{(S)}\right) \right\|_2 \right] + \mathbb{E}_{\mathcal{D}^{(2)}}\left[ \left\| f_R\left(x^{(R)}\right) - f_D\left(x^{(D)}\right) \right\|_2 \right] - Robust side information. Side information (e.g. skip connections) plays a key role in cross-modal translation problems, by providing helpful structural information at different scales and levels of abstraction so the decoder can better solve the task with the help of the encoder. We analyze several types in more detail in the next section.
During test, unseen translators are assembled by concatenating the corresponding encoder and decoder. The following figure shows the depth-to-segmentation translation
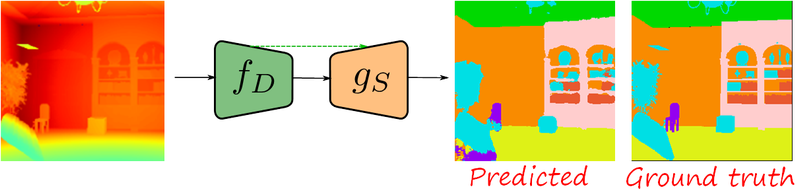
Note that this method manages to predict more accurate segmentation maps, even for small objects.
Side information
A simple encoder-decoder architecture relies solely on the latent representation in the bottleneck to reconstruct the target image. A lot spatial details are lost in the encoding process.

However, some additional hints in the form of side information can be passed to the decoder from the decoder (see figure). In general, these hints go from one encoding layer to the corresponding mirrored layer in the decoder, providing the decoder with helpful information about the spatial details and level of abstraction. The role of side information is very important to solve cross-modal translation problems, such as semantic segmentation and depth estimation.
Perhaps the most common form of side information is skip connections, which copy feature maps from the encoder to the decoder. In particular, we use the UNet architecture, where those feature maps are then concatenated with the corresponding mirrored layer. Another type of side information is pooling indices, used in the SegNet architecture. In this case the encoder has max pooling layers for downsampling the feature maps which are paired with the upsampling layers in the decoder. During pooling, not only the maximum value is saved, but also the index of the input value that had that value. This information is shared with the upsampling layer of the decoder.
Note that when side information is used, the decoder becomes conditioned on the encoder, and that is a problem for unseen translations, since the decoder may not know how to use the side information from this unseen encoder, and it can break the whole communication. Here we can see what happens
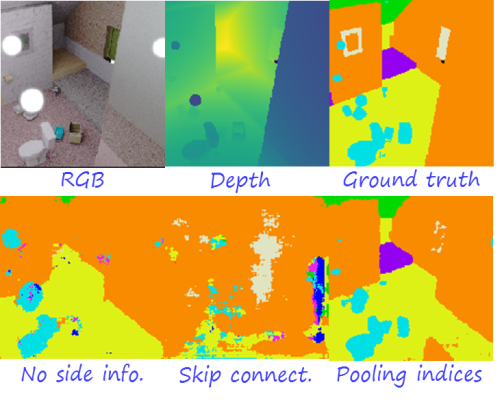
Side information that is heavily dependent on a particular encoder, such as skip connections, is not suitable for unseen translations, while more compact, relatively encoder-independent side information is better suited to unseen translations. Note that skip connections lead to worse results that no side information at all, while pooling indices have significant advantages, for instance, in small objects and finer details. The previous example is representative and consistent with the evaluation scores in the test.
| Side information | Pretrained | mIoU | Global accuracy |
| – | N | 32.2% | 63.5% |
| Skip connections | N | 14.1% | 52.6% |
| Pooling indices | N | 45.6% | 73.4% |
| Pooling indices | Y | 49.5% | 80.0% |
In conclusion, we analyzed the problem of inferring unseen translations between domains (modalities) in multi-domain (multimodal) image-to-image translation. Mix and match networks address this problem by enforcing seen and unseen encoders and decoders to align, resulting in more domain (modality) invariant latent representations. Any unseen translation can be then implemented by simply concatenating the encoder and decoder of the input and output domains (modalities).
References
Y. Wang, L. Herranz, J. van de Weijer, “Mix and match networks: multi-domain alignment for unpaired image-to-image translation”, International Journal of Computer Vision, vol. 128, no. 12, pp. 2849–2872, Dec. 2020 [arxiv] [link].