
The problem of catastrophic forgetting (a network forget previous tasks when learning a new one) and how to address it has been studied mostly in discriminative models such as image classification. In our recent NeurIPS 2018 paper (video), we study this problem in an image generation scenario and propose Memory Replay GANs (MeRGANs) to prevent forgetting by replaying previous tasks.
This post assumes that you are familiar with conditional generative adversarial networks (a.k.a. conditional GANs). Otherwise you may consider reading a previous post about that topic. I will also talk about lifelong/sequential learning, which I also covered previously.
Generating images with GANs
Generative adversarial networks are the state-of-the-art approach to generate realistic images of a particular domain. If you have a dataset with animals (say dogs, cats and birds), a GAN can capture the visual distribution so then can generate other images of animals. The input is just a (latent) vector z which is converted to a particular image of an animal. However, you cannot control which type of animal you are generating. With class-conditional GANs you can further control the category you are generating with an additional input c (the condition). Then we can ask the network to generate a dog, cat or bird, just changing the value of c.
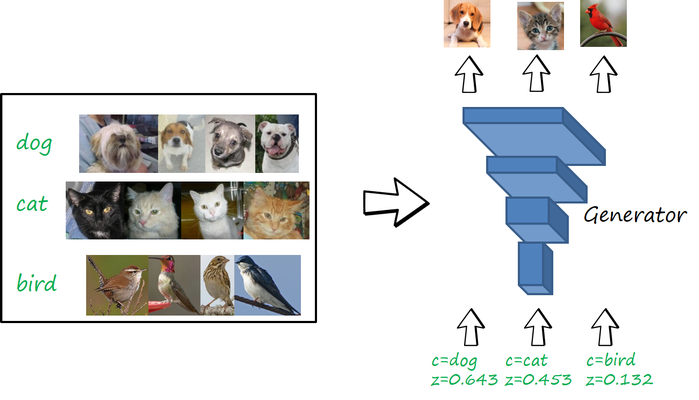
Note that the conditional GAN has learned the three domains at the same time, and can generate images properly for any of them. If we consider each domain as a different task, in this multi-task setting, the network remembers to perform the three tasks.
Sequential learning meets image generation
Now we consider the case where we learn each task independently and in sequence, i.e. we learn first to generate dogs, then to generate cats and then to generate birds. After training each task, you change the training set and continue training. Let’s call this process sequential fine tuning (SFT). This is what happens
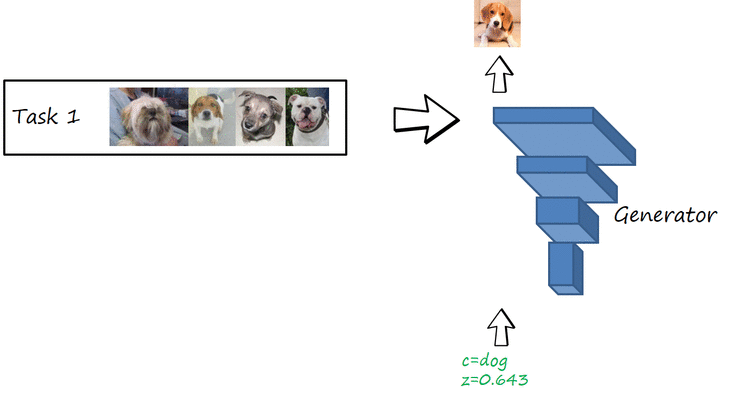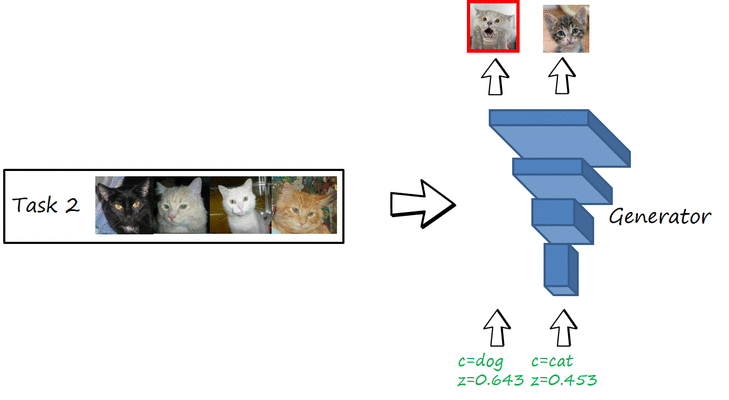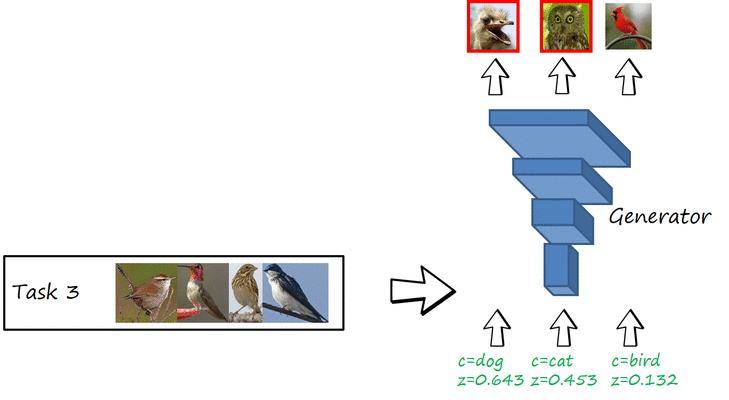
Catastrophic forgetting in image generation
As you can see in the previous figure, when the networks learns to generate cats, it also forgets how to generate dogs, and when learns to generate birds it also forgets to generate cats. That is, the network is only able to remember the last task and suffers from catastrophic forgetting. The following two figures illustrate the same phenomenon but with actual datasets and an actual GAN (we use a conditional GAN with Wassserstein GAN with gradient penalty loss, a.k.a WGAN-GP).


The example on the left illustrates catastrophic forgetting with the dataset LSUN, where we learn sequentially four tasks: generate the categories bedroom, kitchen, church and tower (in this order). As in the previous illustration, the network is unable to generate images from previous tasks. In all the images the latent vector z is the same. The example on the right is trained with the popular dataset MNIST, where each task consists of learning to generate a digit (from 0 to 9, in this order). After learning the tenth task, the network is only able to generate 9s, regardless of the digit we request. Each column correspond to a different latent vector (randomly sampled).
Memory replay generative adversarial networks (MeRGANs)
Forgetting is mostly caused by the interference between learning the new task and previous ones, since both are using the same parameters. Optimizing the parameters for the new task makes them move away from the previous solution for the previous one (more insight here).
In order to address this problem we propose MeRGANs, which are based on the mechanism of replaying memories (i.e. imagining images) from previous tasks to consolidate them while learning new tasks. After training a task, we make a copy of the generator (let’s call it replay generator). Its parameters are frozen so they won’t change with the new task, while the other generator will. This prevents interference in the replay generator, and therefore prevents forgetting. Now, it will interact with the other generator to prevent forgetting of previous tasks while learning the new one. Although the interaction could be between the weights of both generators (as proposed here), we make them interact via activations (i.e. generated samples). We propose two ways.
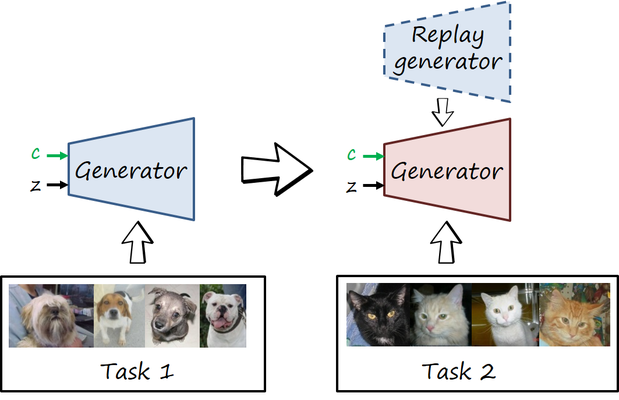
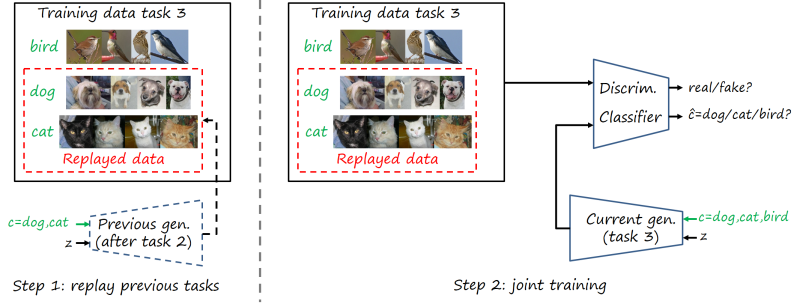
Joint training with replay (MeRGAN-JTR)
This first method basically creates a new dataset combining the real data available for the new dataset (e.g. birds), and samples generated by the replay generator from previous tasks (e.g. dogs, cats). Then the network is trained jointly with this new dataset with category labels (we use the AC-GAN model combined with WGAN-GP).
Replay alignment (MeRGAN-RA)
The second methods relies on aligning the images generated by both generators. In this case there are two separated mechanisms: prevent forgetting in previous tasks, and learning the new task. In the former, the same random input pair \left(c,z\right) (c could be from any previous task, e.g. dogs, cats) is fed to both generators, and their outputs are forced to align by using a pixel-wise loss. The latter conditions on the new task (e.g. birds) and trains the model as a conventional GAN using only data from the new task.
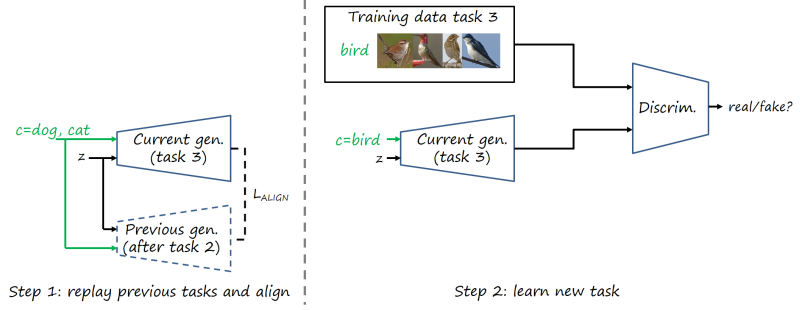
Note that we can align the outputs of both generators because before starting to learn the new task both are exactly the same network by construction (we duplicated it). Therefore, the same input pair \left(c,z\right) will produce exactly the same output image, and we can force them to align at the pixel level with a pixel-wise loss (we use L2 loss). During the learning process, we want that that situation (same outputs for the same inputs) keeps the same for previous tasks, while allowing the generator to still learn when conditioned on the new task.
Experiments
Imagining digits (MNIST)
The next video illustrates the process of learning new tasks and (not) forgetting previous ones via digit generation in the MNIST dataset (32×32 pixels, each digit is a different task). We also compare with a baseline that forces aligning the parameters of the generator (using EWC as proposed here), rather the outputs.
In general, sequential fine tuning manages to learn to generate realistic digits of each current task, but forgets completely previous ones, as we showed before. In contrast, MeRGANs can generate realistic digits while still remembering previous ones, with better quality than EWC.
Imagining scenes (LSUN)
We observe similar learning and forgetting dynamics in the more challenging setting of LSUN (64×64 pixel color images of scenes). MeRGANs manage to remember previous tasks, while still generating competitive images.
Preventing forgetting at category level and instance level
In this last video, we can observe some interesting differences between MeRGAN-JTR and MeRGAN-RA (also in MNIST, but here is clearer). Note that MeRGAN-JTR generates bedrooms (and the other categories) in general, with the bedroom generated for a particular pair \left(c,z\right) changing across the different iterations. However, MeRGAN-RA generates always the same bedroom, because the replay alignment enforces generating always the same instance. The two different mechanisms prevent forgetting at the category level and at the instance level, respectively.
Visualizing catastrophic interference and forgetting
Another interesting phenomenon we can observe in the previous video is the interference between tasks and how that causes forgetting. Watch the video again and pay attention to the transition between task 2 kitchen and task 3 church (especially the first iterations). The next figure focuses on those iterations.

A very salient artifact during that transition is that bedroom images turn bluish (e.g. walls) for a few iterations. Our hypothesis is that during the transition between indoor to outdoor scenes (kitchen to church in particular) the network has to learn to generate the blue sky, which fills a large portion of church images. However, the network is not equipped with that ability, and has to allocate it in a network where all the capacity is used. Thus, during a few iterations, generating blue skies interferes with generating walls and other characteristics of bedrooms and kitchens. Fortunately, the replay mechanisms help the network to reallocate and redistribute its capacity to provide the ability to generate task-specific features without interference. Note that the interference is more evident in MeRGAN-JTR.
Sequential learning and forgetting in t-SNE visualizations
A different perspective of the sequential learning process can be observed via t-SNE visualizations. Here we train a classifier on real MNIST data and use it to extract features from generated data. Then we use t-SNE on the resulting embeddings, and visualize the results. If we compare the 0s generated by the different methods after learning the ten tasks (see next figure), we observe that the images generated by sequential fine tuning and EWC are significantly different from real 0s, appear as different clusters. In contrast, the images generated by MeRGANs are mixed with real 0s and distributed in a similar way (at least in the t-SNE visualization).
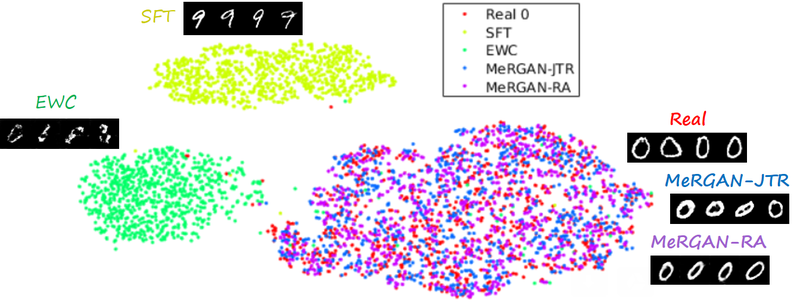
Another interesting visualization comes from fixing the method and visualizing the evolution of features generated for a certain category after learning each task. In the following examples we focus on the digit 0.
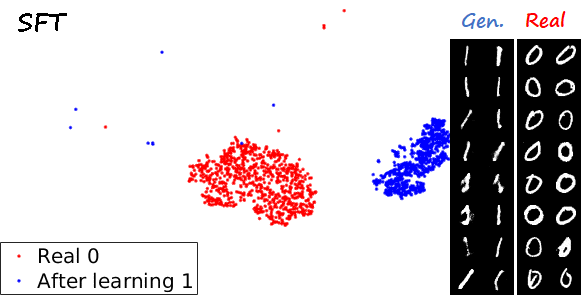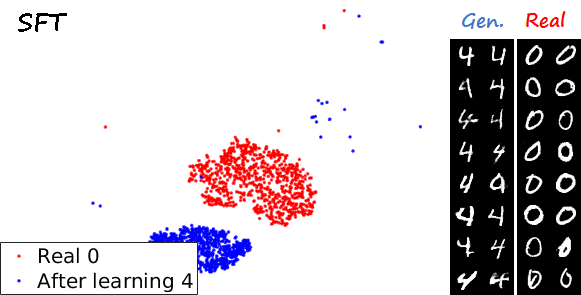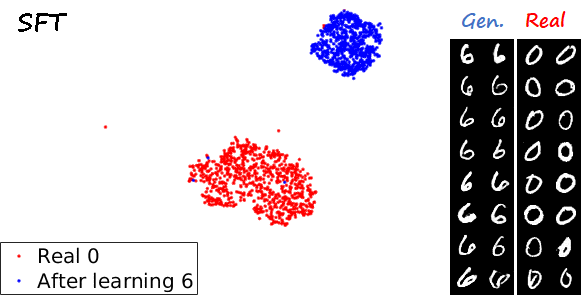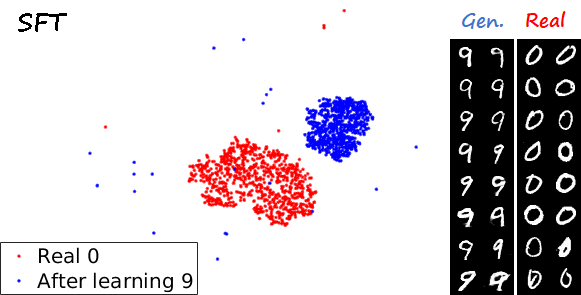
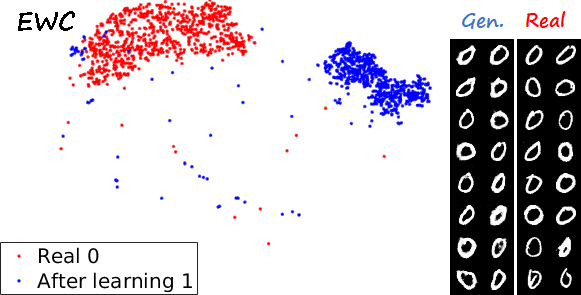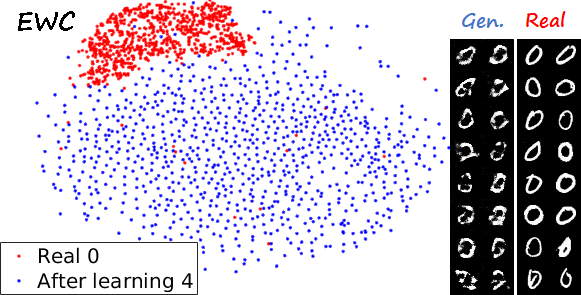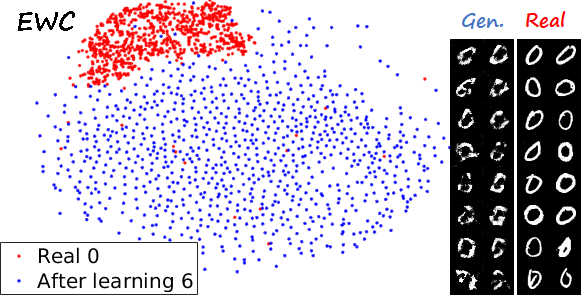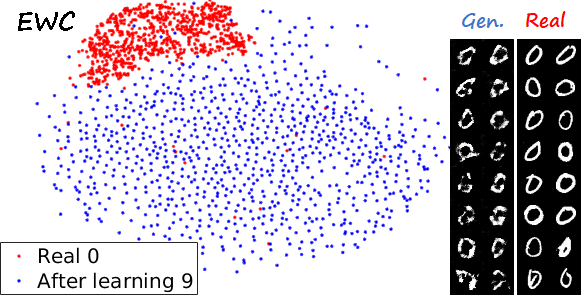
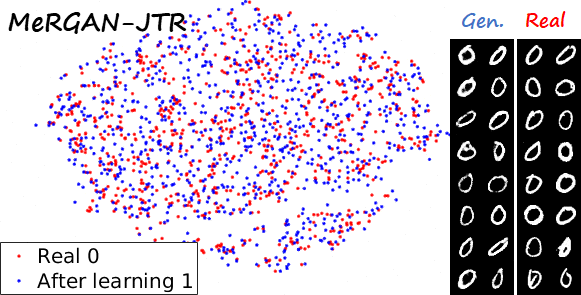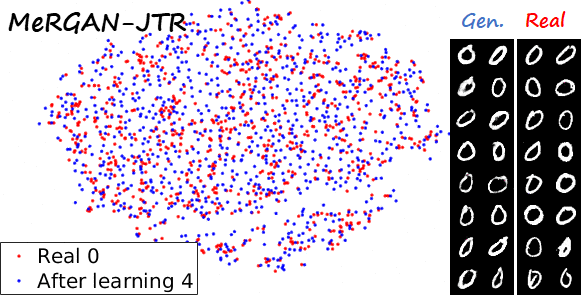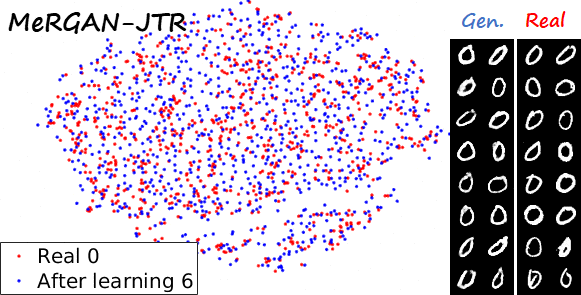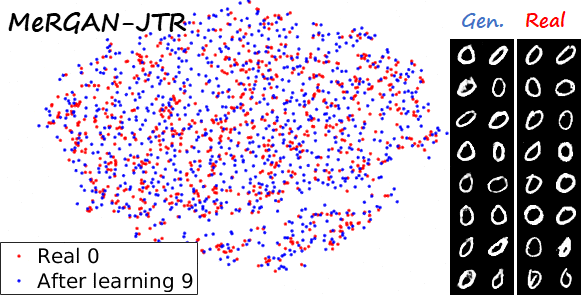
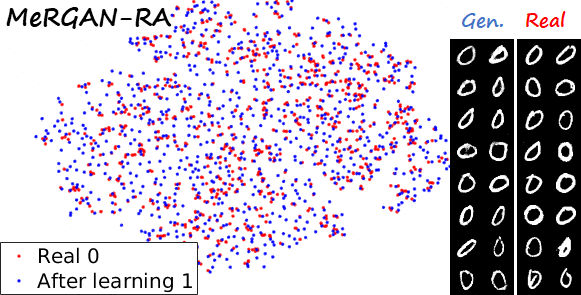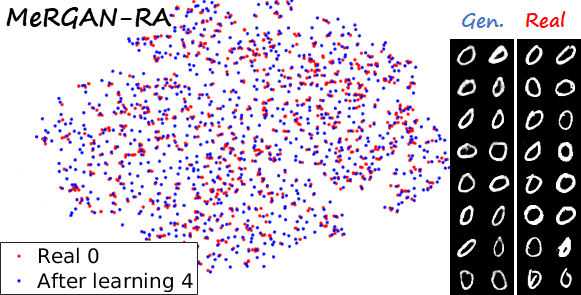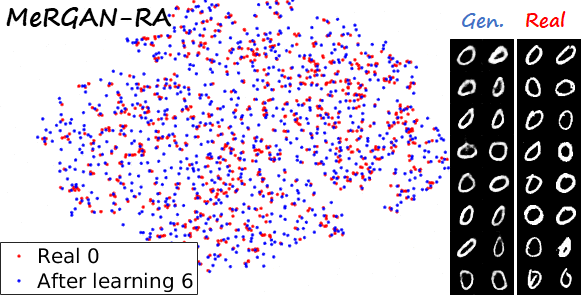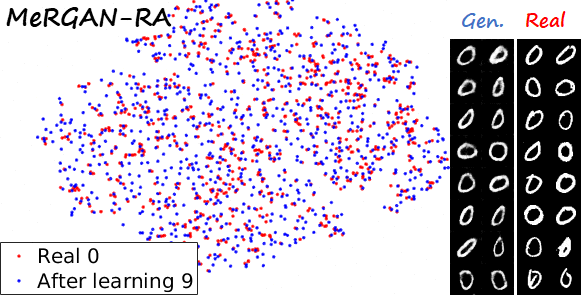
Note again how real digits and digits generated by MeRGANs appear distributed in similar ways. However for MeRGAN-JTR there is significantly more change in the visualized dots than in MeRGAN-RA, which also illustrates the differences between preventing forgetting at category and instance levels.
Conclusion
Image generation provides an alternative and interesting way to analyze sequential learning. We can directly observe learning and forgetting through the evolution of generated images. Catastrophic forgetting can be greatly alleviated with memory replay GANs, and the mechanisms of joint training with replay and replay alignment, which enforce remembering the category and the instance, respectively.
Reference
C. Wu, L. Herranz, X. Liu, Y. Wang, J. van de Weijer, B. Raducanu, “Memory Replay GANs: learning to generate images from new categories without forgetting”, Proc. Neural Information Processing Systems (NeurIPS), Montreal, Canada, Dec. 2018 (accepted) [arxiv] [code] [slides].
X. Liu, C. Wu, M. Menta, L. Herranz, B. Raducanu, A. D. Bagdanov, S. Jui, J. van de Weijer, “Generative Feature Replay For Class-Incremental Learning”,CVPR Workshop on Continual Learning on Computer Vision (CLVISION 2020), June 2020 [arxiv] [code].