
Can we perform unsupervised domain adaptation without accessing source data? Recent works show that it is not only possible but also very effective. In
Read MoreAuthor: lherranz
Protected: Improving the perception of low-light enhanced images
There is no excerpt because this is a protected post.
Read MoreCompression for training on-board machine vision: distributed data collection and dataset restoration for autonomous vehicles
Unmanned vehicles require large amounts of diverse data to train their machine vision modules. Importantly, data should include rare yet important events that the
Read MoreMAE, SlimCAE and DANICE: towards practical neural image compression
Neural image and video codecs achieve competitive rate-distortion performance. However, they have a series of practical limitations, such as relying on heavy models, that
Read MoreNeural image compression in a nutshell (part 2: architectures and comparison)
Neural image codecs typically use specific elements in their architectures, such as GDN layers, hyperpriors and autoregressive context models. These elements allow exploiting contextual
Read MoreNeural image compression in a nutshell (part 1: main idea)
Neural image compression (a.k.a. learned image compression) is a new paradigm where codecs are modeled as deep neural networks whose parameters are learned from
Read More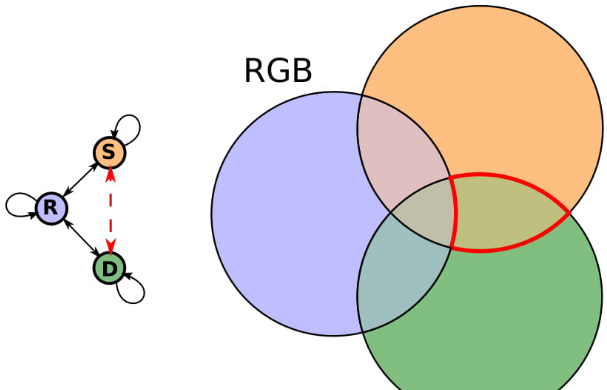
Mix and match networks (part 2)
This is a brief update on mix and match networks (M&MNets), describing the new ideas included in the extended version (IJCV 2020). An earlier
Read More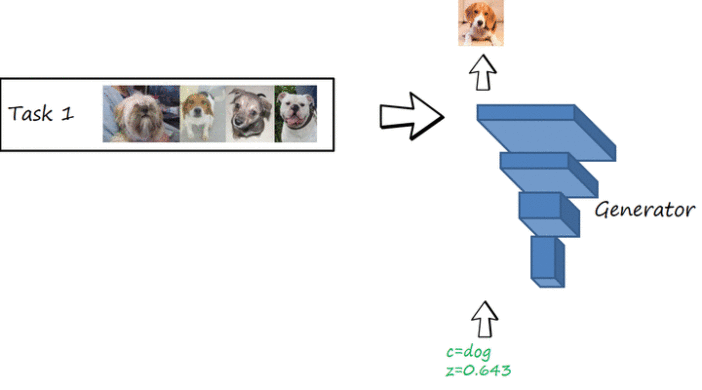
MeRGANs: generating images without forgetting
The problem of catastrophic forgetting (a network forget previous tasks when learning a new one) and how to address it has been studied mostly
Read More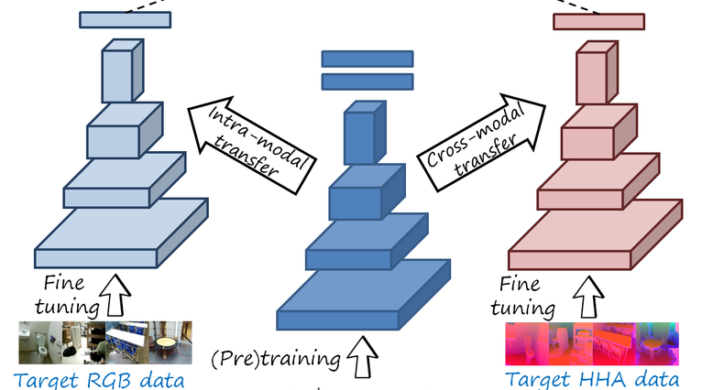
Learning RGB-D features for images and videos
Depth sensors capture information that complements conventional RGB data. How to combine them in an effective multimodal representation is still actively studied, and depends
Read More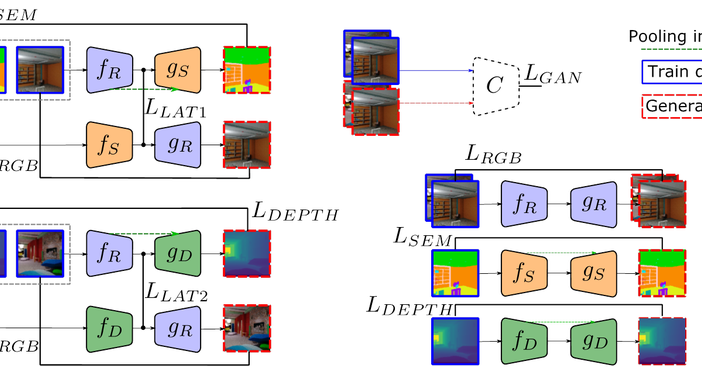
Mix and match networks
We recently explored how we can take multiple seen image-to-image translators and reuse them to infer other unseen translations, in an approach we call
Read More