
Unmanned vehicles require large amounts of diverse data to train their machine vision modules. Importantly, data should include rare yet important events that the vehicle may face while in autonomous operation. In addition, modern vehicles capture data from multiple cameras and sensors. In order to record such massive amount of data within limited transmission constraints or storage space, a possible strategy is the use of image or video compression, so more data can be captured. However, lossy compression may have an impact on the semantic performance of the downstream task. In this post I summarize our analysis of this scenario and the proposed method of dataset restoration.
Traditional image and video coding techniques and standards are designed for human consumption, that is, to be visualized and analyzed by humans. However, recent improvements in machine learning and communication platforms, along with the abundance of sensors and increased connectivity between intelligent devices, a new paradigm termed video coding for machines has emerged to enable advanced communication between machines. MPEG is currently exploring this new direction.
We explore a different aspect of the interplay of image/video coding and machine vision: the impact of image compression in the training of on-board machine vision, where the training takes place in the server but the model is deployed in the vehicle, where it is tested with uncompressed images.
Scenario: collecting training data with a vehicle fleet
We consider the scenario where a fleet of cars, equipped with cameras and sensors, navigates the area of interest continuously capturing data to be used for training the next version of scene analysis modules to be deployed in the vehicles as part of their on-board machine vision system. With such amount of data captured and diversity of sources, the training is centralized in the server. Importantly, note that training takes place in the server while the models are tested in the vehicles.
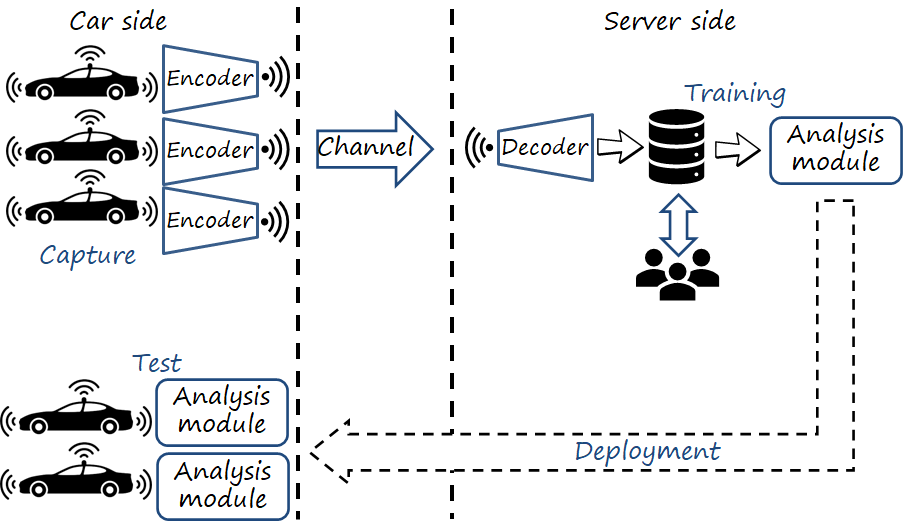
The images (or videos) are transmitted directly to the server, or conversely stored in the vehicle in hard disks subsequently copied to the server. In either case, there exists a key constraint: the transmission (bit) rate (or conversely, the storage capacity) is limited. Under this constraint, the amount of data collected (we focus on images) is also limited. Lossless image compression can increase the amount of collected data. In either (i.e., uncompressed and lossless compression), training data has no losses in fidelity with respect to the capture images. However, we could leverage lossy image compression to achieve significantly lower rates and thus increase the amount of captured data, at the cost of introducing certain degradation of the fidelity of the image (i.e., distortion) during the compression process. If you are not familiar with lossy image compression, I suggest you to read my previous posts on neural image compression (part 1, part 2).
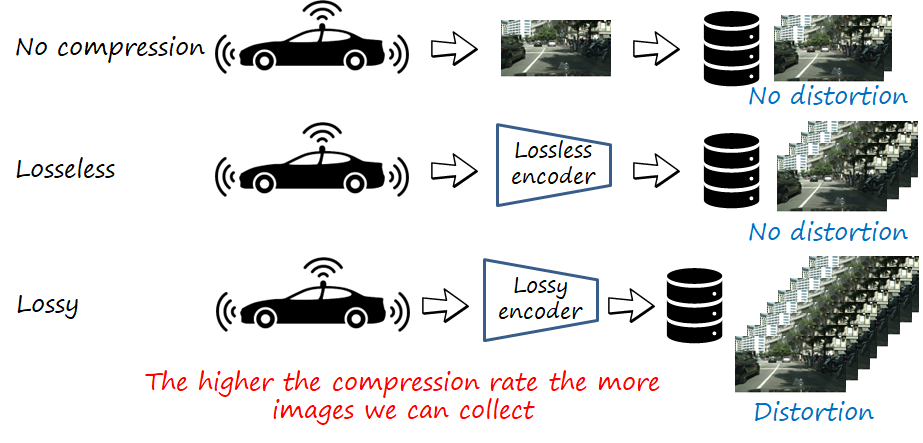
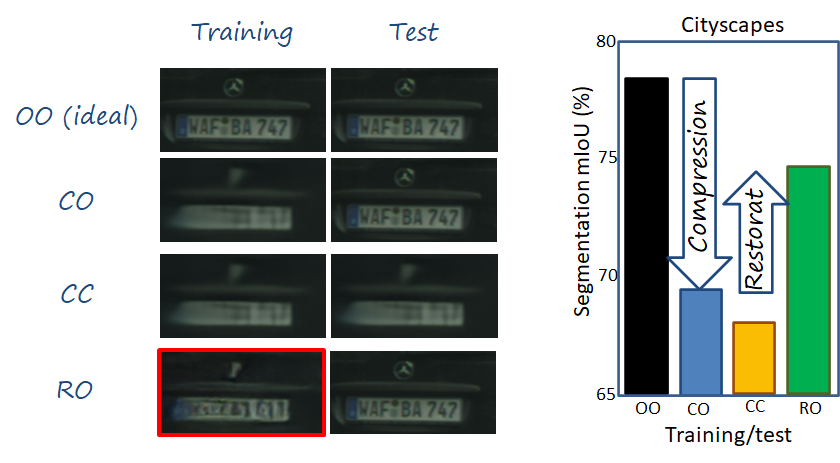
While image codecs are analyzed from the perspective of rate-distortion performance, what are the implications of different rates for the downstream analysis tasks? As we can see in the figure below, the images uses for training are degraded (e.g., blurred) with respect to those used at test time in the vehicle side, since the latter don’t need to be compressed.
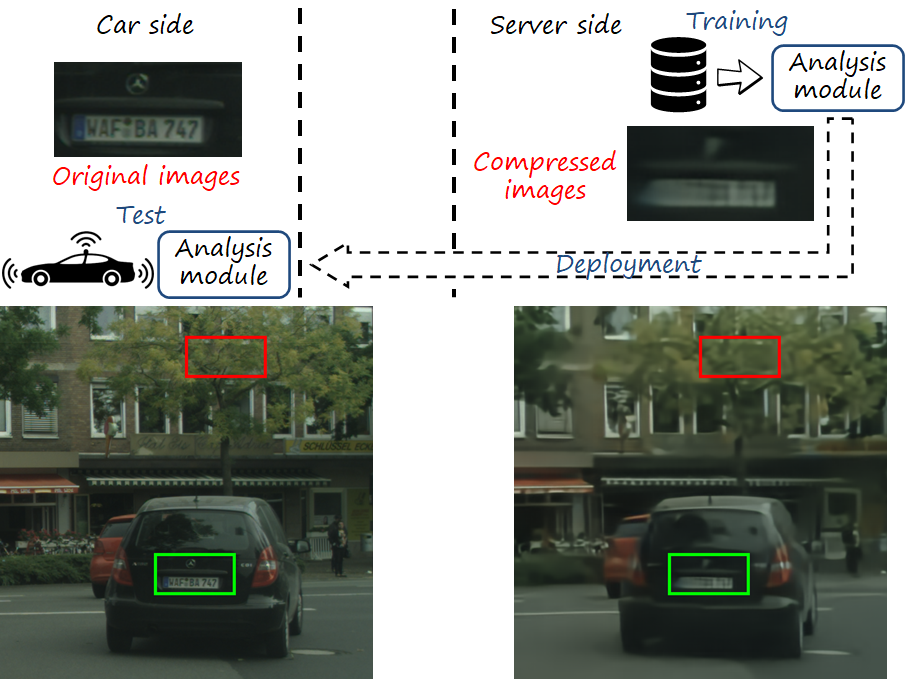
We can see that textures appear degraded (e.g. trees, plate) in training images, but clear and sharp in test images. We can see this is a deviation from the optimal case in which training and test samples are sampled from the same distribution (i.e., the clear and sharp images in this case). Intuitively we can see that the performance of downstream analysis tasks will degrade. In particular, we identify two factors why this configuration degrades the semantic performance.
- Covariate shift. Training and test images are sampled from different distributions (i.e., degraded vs original images) induced by the lossy compression process that training images underwent. Hence, there exists a shift between the training and test distributions.
- Loss of semantic information. In addition, the degradation of training images leads to them conveying less information, which is not only visual but also semantic (e.g., the license plate number is not readable).
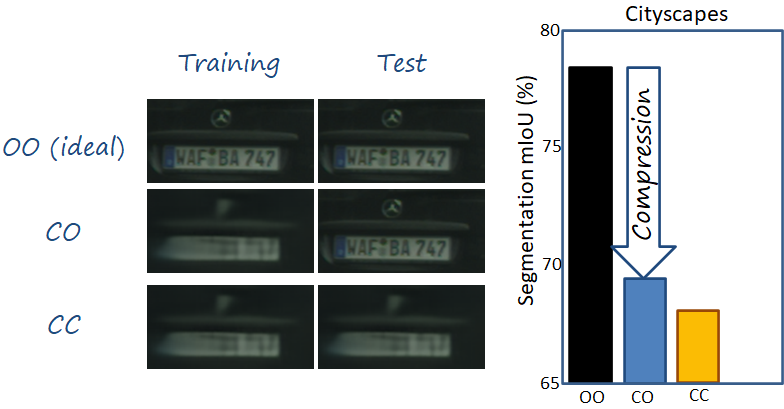
These two factors explain why the semantic analysis performance (segmentation in our experiments) drops, as shown in the figure below. In the following we encode the train/test configuration with letters, where O means original (i.e., captured images in the vehicle), C means compressed (i.e., reconstructed images after compression). In a configuration the first letter refers to the training distribution, and the second to the test one. Thus, the ideal case corresponds to OO, while the case we have been describing corresponds to CO. We can see that there exists a significant drop in performance in the latter.
A simple solution to address this problem is also compressing test images prior to analysis. In this way we ensure that training and test images are sampled from the same distribution (i.e., we address the covariate shift), and the segmentator can model the classes knowing that no additional unknown patterns (e.g. sharp textures) will be presented during test. On the other hand, we are discarding potentially useful visual and semantic information in the test images too. In our experiments, this approach doesn’t help, and in fact contributes with an additional drop in the semantic performance. This suggests that the lost information in test can still be useful, even when they are not seen by the model during training.
Can we alleviate the performance drop? Dataset restoration
It seems that not discarding information during test is important. Is there any way we could recover the lost information due to compression, which in turn, hopefully, can help alleviating the covariate shift? Actually the exact pixelwise information is very likely to be unrecoverable. However, distributional information about the domain, such as textures, and colors, can be somewhat hallucinated using restoration techniques. Thus we propose dataset restoration, a process in which the training images are restored using an adversarial image restoration network. The restored dataset is then used to train the model.
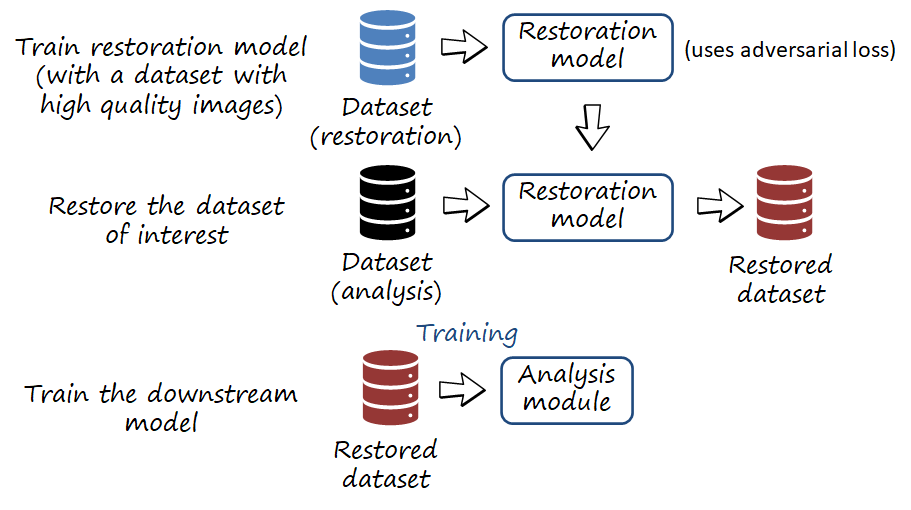
In order to understand the effect of dataset restoration and the relation to covariate shift and loss of information, we can observe the figure below. The restored image looks more realistic than the compressed one, in particular the textures. For example, the highlighted regions contain textures of trees and numbers/letters. While not matching pixelwise the original regions, the textures are visually realistic and more similar (i.e., smaller covariate shift), and convey to the segmentator discriminative information about the texture of leaves and branches, and car plates, which can be helpful to segment trees and cars (i.e., milder loss of information than in the compressed case). Thus, the model can leverage more information and more similar to the test conditions to perform the segmentation task.

The figure below completes a previous one with the configuration RO (i.e., restored training, original test). We can observe the significant increase in performance, which alleviates the overall drop. We can observe that, although the plate doesn’t contain any recognizable number, the overall visual impression looks much more realistic and similar to the original one.
Results
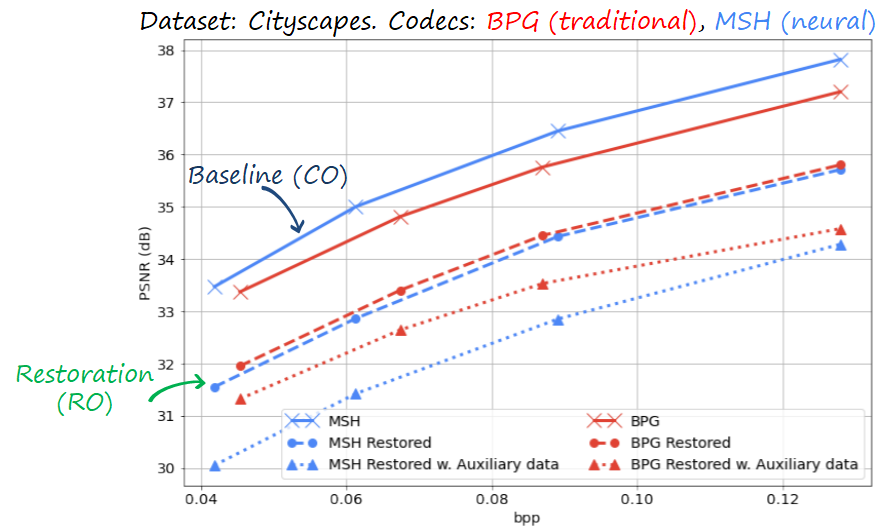
We perform experiments analyzing the distortion and semantic performance for different rates. We studied both the case of a traditional codec (i.e., BPG) and a neural image codec (i.e., mean scale hyperprior). Interestingly, we can observe that the rate-distortion performance degrades with dataset restoration.
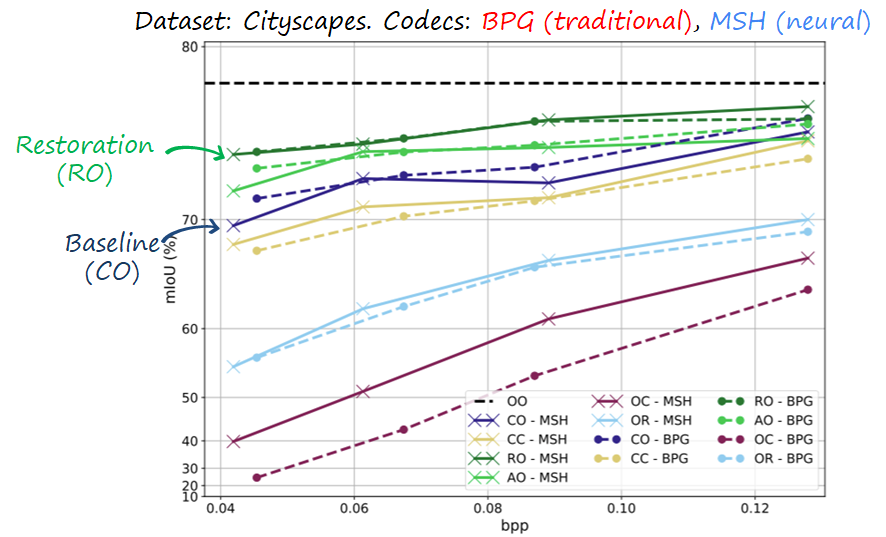
However, when plotting the segmentation performance, we find that dataset restoration is helpful and consistently improves the segmentation performance in both codecs.
Connection to the perception-distortion tradeoff
We found an interesting connection with the perception-distortion tradeoff theory (and its extension to rate-distortion-perception), which states that perception (understood as no-reference perceptual quality metrics) and distortion (with respect to a reference) are at odds with each other. This means that there exists a boundary in the perception-distortion plane beyond which pairs of perception-distortion are unnatainable by algorithms. This boundary is a fundamental limit that depends on the specific degradation. In lossy compression, the severity of the degradation (see figure below) is related to the rate, with lower rates leading to more severe degradations. Thus, a restoration algorithm navigates the perception-distortion plane, but can’t cross the boundary, and close to it, an improvement in perception leads to worsening distortion, and viceversa.
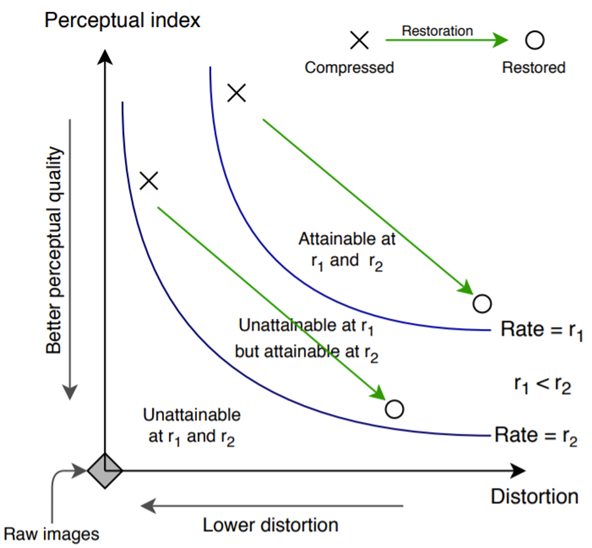
In our case, dataset restoration also changes the operation point of the images in the training dataset. This can indirectly explain the previous results where we observe that dataset restoration harms the rate-distortion performance, while improving segmentation. In fact what seems to improve during restoration is the perceptual quality, as suggested by the perception-distortion tradeoff. In turn, segmentation seems to benefit from improved perceptual quality (e.g. more realistic textures) and that leads to better segmentation performance.
Restoration: adversarial vs non-adversarial
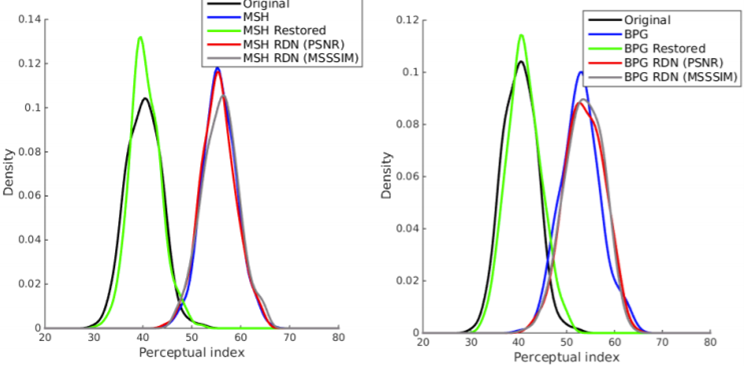
In our experiments we use an image restoration model trained with adversarial loss. We also studied a restoration model without adversarial loss, observing that the results didn’t improve over the CO configuration. If we plot the distribution of perceptual values of the training images, we observe that the non-adversarial loss doesn’t significantly change it, while the adversarial does and in fact shifts it to lower values, significantly overlapping with the real one. The perception-distortion tradeoff suggests that adversarial loss is particularly suitable for measuring perception, since the discriminator mimics humans evaluation of whether an image is real or fake. Thus, adversarial restoration shifts the distribution of perceptual values.
Collection cost
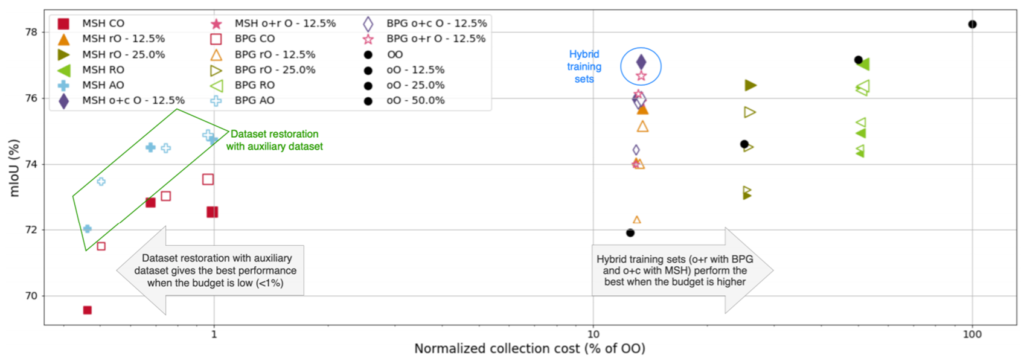
Finally, we address the practical question of the tradeoff between the collection cost and the corresponding semantic performance. Assuming that the cost per bit is constant, we first compute the cost of collecting all images of the dataset of interest using lossless compression. We use that cost as reference and normalize the others with respect to it. We can observe that lower budgets (i.e. resulting in fewer training images) with lossless compression the performance rapidly degrades. In contrast dataset restoration (i.e., RO, and AO, which is a variant) can achieve competitive performance with a small fraction of the cost using this baselines OO and CO.
References
S. Katakol, B. Elbarashy, L. Herranz, J. van de Weijer, A. M. Lopez, “Distributed Learning and Inference with Compressed Images”, IEEE Transactions on Image Processing, vol. 30, pp. 3069-3083, Feb. 2021 ![]() [arxiv] [link] [slides].
[arxiv] [link] [slides].
Y. Blau, T. Michaeli, The Perception-Distortion Tradeoff, CVPR 2018.
Y. Blau, T. Michaeli, Rethinking Lossy Compression: The Rate-Distortion-Perception Tradeoff, ICML 2019